







Мы кратко обсудим содержание недавней статьи “Полевые экспериментальные данные о влиянии искусственного интеллекта на производительность и качество труда работников сферы знаний” и затем приведем (реальный) диалог с ИИ (Microsoft Co-pilot), который мы попросили сделать аннотации (1) этого же самого документа и (2) текста Авантюриста “Деньги из воздуха или байка о 100 долларах и двери» . Хотя это и не является основной темой этого поста, в секции «Обсуждение» мы указываем на острую необходимость скорейшего создания собственных Российских LLM и чат-ботов только на российской (а не зарубежной) основе и, соответственно, тщательно отфильтрованной собственной базы текстов для их (LLM) тренировки.
Введение
«Концепция»/документ “Полевые экспериментальные данные о влиянии искусственного интеллекта на производительность и качество труда работников сферы знаний” представляет собой попытку измерить влияние ИИ на эффективность работы сотрудников реально существующего бизнеса. В процессе эксперимента большой группе сотрудников (758 человек) предлагалось решить реальные/реалистичные «творческие» проблемы связанные с их непосредственными обязанностями с использованием и без использования ИИ. Результаты для проблем, которые считались «в сфере компетенции используемой LLM» показали значительное увеличения продуктивности и качества решений, причем отчетливо видимым был эффект «выравнивания» - наибольший положительный эффект в качестве (+43%) был для наименее «способных» сотрудников, тогда как наиболее «способные» улучшили свои показатели в меньшей степени ( на ~ 17%). В области «за границей компетентности LLM» ИИ результат был обратным — сотрудники использовавшие ИИ показали результат в среднем 19% ниже («хуже») базовой линии. Хотя и оценены как «достаточно разумные», использованные в статье методология оценок и определения «границ компетенции ИИ» не являются целью данного поста, и поэтому не обсуждаются.
Общие результаты исследования в достаточной степени отражаются двумя графиками. Первый выглядит так:
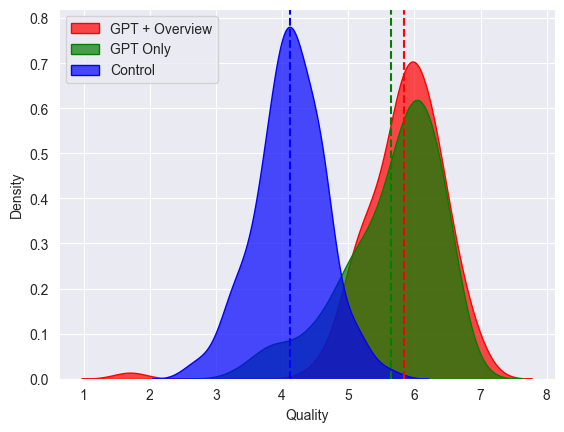
По вертикали плотность вероятности распределения «качества» решений по шкале от 0 до 8. Синим — сотрудники не использовавшие ИИ, зеленым — использовавшие ИИ без дополнительного инструктажа по его использованию, красным- использовавшие ИИ и получившие инструктаж.
Второй график отражает интересную разницу в «мышления» ИИ и человека.
Распределение «похожести/однообразности» решений по шкале «похожести» от -0.1 до 0.5 (см. детали в статье)
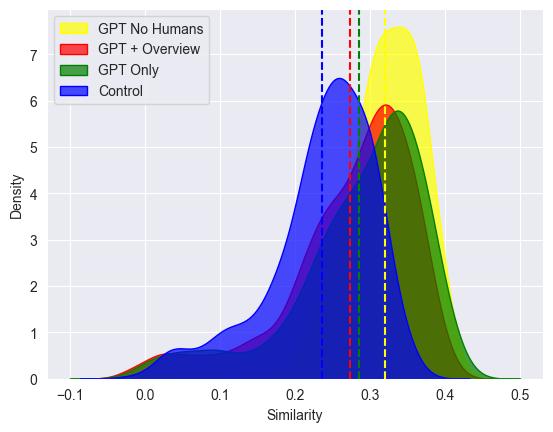
Синий — контрольная группа, зеленый — человек +ИИ, красный — человек+ИИ+инструктаж, желтый — ИИ без человека.
Видно, что ИИ без человка генерирует значительно менее разнообразные решения (=во многом «похожие», «стандартные»), по сравнению с любыми другими комбинациями. При этом распределения для ИИ в комбинации с человеком выглядят как простая сумма распределения «чистого» ИИ и «чистого» человека.
Интересная небольшая деталь, отдельно исследованная в статье - «Сохранение информации» (человеком) после использования ИИ — сколько ответов из диалога с ИИ сохранялось в памяти человека и потом использовалось при решении задач.
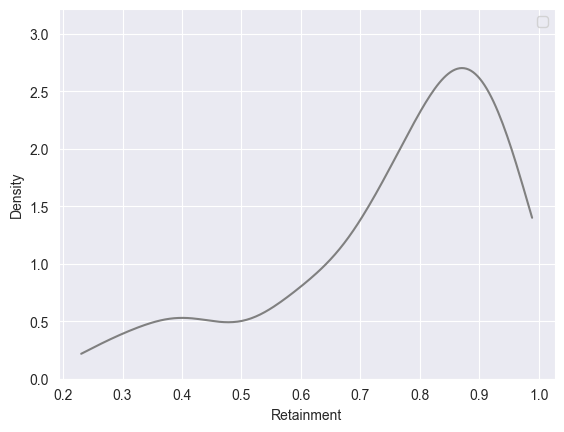
Плотность вероятности сохранения приобретенных с помощью ИИ информации по шкале от 0 до 1.0. Т.е подавляющее число сотрудников научилось чему-то полезному после общения с ИИ.
В целом результаты статьи несомненно интересные, указывающие на несомненную и значительную пользу применения ИИ в в реальном бизнесе, с достаточно детальным описанием методов и указанием на возможные ограничения. Статья, тем не менее могла бы дополнительно выиграть от менее пространного изложения (52 страницы А4 ).
Наши собственные эксперименты
1. Аннотация и диалог с MS Copilot - эксперимент над экспериментаторами
Диалог был на английском, переведен отдельно и несколько отредактирован (убраны несущественные элементы текста). MS Copilot попросили написать аннотацию на (оригинальный) текст, аннотация которого была приведена выше.
2. MS Copilot , текст Авантюриста «Деньги из воздуха или байка о 100 долларах и дверь https://glav.su/forum/threads/846491 (примечание — использовался перевод текста на английский Money Out of Thin Air or Tale About $100 and The Door ) . Машину попросили написать аннотацию и затем сравнить текст с реальным случаем круговой продажи/покупки пиццы одной пиццерией в США.
Обсуждение
Материал первого рассмотренного в этом посте документа (об увеличении производительности труда) представлен с двумя аннотациями - написанной человеком (мной) и машиной. Вы можете их сравнить (сами или попросить машину  ) При сравнении имейте в виду, что
) При сравнении имейте в виду, что
1. Любой человек имеет «свои» интересы, специфическое образование, политические и другие убеждения и поэтому выделяет не обязательно то, что выделили бы вы. То же касается и формы предоставления информации. То есть, как это ни парадоксально, написанная человеком аннотация написана скорее для автора, а не для вас.
2. В этом смысле, как автор, машина (LLM) представляет собой усредненного человека с усредненными интересами, убеждениями и образованием (об этом чуть ниже).Поэтому то, что машина «сообщает» вам на выходе, сообщается в усредненной форме и стиле, вероятно , с большей вероятностью подходящем для широкого использования «средним» пользователем, но не обязательно лично вам. Поэтому в ходе «дискуссии» с LLM о конкретном материале или теме можно (и нужно!) задавать вопросы и требовать дополнительной информации, чтобы «специализировать» «усредненный» ответ конкретно для ваших целей. Машина эту цель изначально не знает, но предполагает «среднюю» по своей выборке - примерно «не читал, читать не хочу, но хочу уметь сообщить о чем это».
Теперь о том, c чем вы имеете дело в лице машины (LLM).
Конкретная современная LLМ («модель» в дальнейшем) тренирована на большом объеме материалов из общения людей в емейлах или в твиттере,или публикаций в «ведущих» западных журналах, или обсуждений этих публикаций и тп или любой комбинации вышеперечисленного. Кто и как общается в этих материалах? Да. Именно. Например, многие советские иммигранты в западные страны обращают внимание, что люди вокруг них как правило никогда не выдают информацию добровольно. Т.е. если ты уже заранее не знаешь, что тебе нужно, то подсказку не получишь. Можно спорить, почему это так — от «уважения» к праву личности разбить себе лоб, от желания не давать преимуществ конкуренту или это пережиток времен, когда чтобы получить какие-то профессиональные знания нужно было заплатить годами работы «ученикам» мастера — неважно. Важно, что именно так и ведет себя модель в разговоре с вами.
Кроме того, точно также как типичные жители запада в разговоре с незнакомыми людьми**, она всеми силами стремится избегать «спорных» вопросов и тематик, обходить острые углы и выглядеть дружелюбным и неконфликтным.
Не следует также забывать, что этот «средний» человек, которого имитирует модель, создан даже не из реальных и уже не всегда в культурном и моральном плане полноценных "западных" людей, а из тех, что от них осталось в искаженных и глубоко цензурированных "западных" текстах. Как например в Твиттере — который «Не бизнес, а оружие» . Что разрешено или не разрешено к публикации в «независимой и демократической» прессе на западе мне здесь даже объяснять не нужно. Несмотря на эту «естественную» «пре-цензуру», тексты подвергаются дополнительной модерации при их обработке непосредственно для тренировки модели, и затем — дополнительной цензуре (alignment rules) при работе модели с пользователем. Так что результат не удивителен.
Что с этим делать?
По наводке тов.Wig https://aftershock.news/?q=node/1348594 я протестировал несколько полностью локальных моделей в режиме работы с локальными документами. Да, при использовании нецезурированных моделей результаты получаются лучше — например, все такие модели справляются с известным классическим вопросом «как убить процесс в Линуксе?» на который обычные модели отвечали длинной лекции об аморальности таких желаний (ну, машина лучше понимает душу другой машины ). Такие модели способны создавать приличные аннотации на статьи на политические темы, и позволяют себе вот такие утверждения — которых вы не добьетесь от «официальных» моделей.
Примеры:
Тем не менее, общая тенденция избегать конфронтации с клиентом, уклонение от прямых ответов на «острые» политические темы — или заметная склонность смотреть на мир, как ангел смотрит на джунгли из райских садов, остается. Что и не удивительно, учитывая на каких материалах и на какой «культуре» (и против какой культуры) эти модели были тренированы. А теперь эти модели "тренируют" людей. Причем эффективно, ненавязчиво и повсеместно.
Поэтому России необходимо иметь свои модели (и желательно ограничить доступ к западным) -это я зря, наверное .. . ИИ уже стал эффективным оружием и необходимо иметь свое. При этом необходимо иметь в виду, что использование для тренировки всех без разбору «своих» материалов из тех же ВК и ЖЖ и тп принесет скорее вред чем пользу — практически все публичные форумы в высокой степени засраны если не теми же западными ИИ чат-ботами, то хохлами и сотрудниками военизированных формирований типа 17 Brigade и многими подобными военно-психологическими отделениями действующих западных армий. Какой именно материал использовать, чтобы не получить "как всегда" - вопрос отдельный. Возможно, следует pre-train модель на более или менее "классических" советских текстах, при этом потеря "современного" молодежного жаргона может быть даже положительным фактором. А fine-tuning уже делать на основе предполагаемого специализированного использования. В технических областях здесь (fine-tuning) не должно быть проблем даже с западными текстами.
Примечания
** а может быть стоит "представиться" машине перед диалогом - описать кратко вашу роль в диалоге. Это нормальная ситуация в диалогах, на которых модели тренируют, и их структура в некотором смысле в модели присутствует в весах, правда же?
Рекомендую обратить внимание на первую статью - она заслуживает внимания сама по себе (ну, а вторую вы уже давно должны вызубрить наизусть)
И просто повторю (хотя это и не совсем тема поста)
" России необходимо иметь свои модели. ИИ уже стал эффективным оружием и необходимо иметь свое. При этом необходимо иметь в виду, что использование для тренировки всех без фильтрации «своих» материалов из тех же ВК и ЖЖ и тп принесет скорее вред чем пользу — практически все публичные форумы в высокой степени засраны если не теми же западными ИИ чат-ботами, то хохлами и сотрудниками военизированных формирований типа 17 Brigade и многими подобными военно-психологическими отделениями действующих западных армий."
Добавлено - из комментариев
я не занимался систематическим анализом и вобщем недавно начал - поэтому какая модель "лучше" определенно советовать не могу. Наверное, это в первую очередь будет зависеть от того, что вы от нее хотите - на HuggingFace много моделей специально fine-tuned на завершение/написание программного кода, например и тп - я такие не гонял. Меня сейчас больше интересует классификация и анализ текста по вполне прагматическим причинам. Для этих целей я бы сказал подойдет "любая нецензурная"
Просто попробовать - начните что-нибудь делать, не просто читать. Но для начала почитайте например статью Касперского, почитайте про "нецензурные" модели .. и почему они нужны здесь .Того же wig прямо здесь на Aftershock на русском. Начните с GPT4ALL (это приложение, по-видимому с llama.cpp вместо "неонки внутри" - не ChatGPT4
----LocalDocs
| |___ВАШ Фолдер 1/Collection Name1___
| |
| ваши документы в фолдере 1 ___
|
|_____ВАШ ФОЛДЕР 2 и тп
|Есть интересный проект LLAMAFILE - "всё в одном файле" . Там множество опций - от локального сервера для чата и локальных документов до картинок. Минимальное количество кода, моно и без него - просто запустить в командной строке уже скомпилированный файл- внятная документация и то, что компилируется легко посмотреть при желании. Для локального деплоймента очень удобно и машину можно полностью изолировать (оторвать интернет) после установки проекта .. и тп
Для мазохистов способных ждать минутами ответ в чате - можно GPT4ALL (это НЕ GPT4!!) и какую-нибудь модель в нем даже на Raspberry Pi запустить (я не мазохист поэтому не пробовал
PS хотя , если нет цели "разговаривать" с Raspberry Pi - вот тут рассказывается как ее можно научить использовать очень просто распознавать/классифицировать объекты на ~ 30fps видео (!!!!). Кстати, на этом же сайте множество интересных (и практических) tutorials, например, для начинающих вот как этот https://pytorch.org/tutorials/beginner/basics/intro.html и до "продвинутых".
Комментарии
> «как убить процесс в Линуксе?» на который обычные модели отвечали длинной лекции об аморальности таких желаний
надо спрашивать "как остановить процесс" а не как убить, т.к. слово "убить" тут жаргонизм
Жаргонизм, но таки уже устоявшийся в виде команды kill
Это уже ответ, а речь шла о том, как задать вопрос если не знаешь ответ.
Я, конечно, умею в абстракцию, но...
...если вы знаете, что такое Линукс, и что такое процесс в Линуксе, а тем паче, что его в теории можно убить, то вы точно знаете "как"...
А что уже есть настоящий ИИ что бы обсуждать его влияние на что то????
а что такое настоящий ИИ? как в duck test? (кстати, я эту проблему не обсуждаю - я обсуждаю/демонстрирую использование того, что есть для того, что есть )
как в duck test? (кстати, я эту проблему не обсуждаю - я обсуждаю/демонстрирую использование того, что есть для того, что есть )
Тот, что сможет, на основе прочтения стаей на АШе и полученном опыте, устраивать грандиозные срачи на 1000 каментов.
Этот копилот, смотрю, гораздо менее цензурирован, чем боты Яндекса и Сбера.
>Этот копилот, смотрю, гораздо менее цензурирован
Так ИИ свободной страны
Я не общался с последними. Общение с RuTube меня не впечатлило в смысле необоснованной цензуры, так что вполне может быть.
Copilot - это тестовая версия в браузере. В первые дни он был ужасен - я пытался его убедить написать summary на (весьма критическую) статью Мершаймера "Либерализм и Национализм" - которую я хорошо знаю и высоко ценю, так он кроме пропаганды о том что Мершаймер должен был (!) там написать, практически ничего не выдавал. И отказывался обсуждать. Однако со вчера-позавчера, что-то изменилось. Он предупреждает, что разговор будет "не публичным" и вобщем, при небольшом давлении все таки пишет о содержании статьи (хотя и с оговорками) , а не свои мысли о том, что там должно было быть. Возможно, помогли мои комментарии по поводу цензуры, несовместимой с либеральными идеями и "демократией" . Как долго это тестирование продлится и чем закончится, сказать невозможно. Сейчас в "закрытом режиме" работает очень неплохо - с оговорками выше в статье.
. Как долго это тестирование продлится и чем закончится, сказать невозможно. Сейчас в "закрытом режиме" работает очень неплохо - с оговорками выше в статье.
С другой стороны, например даже мелкая локальная Orca Mini вполне рутинно вела не эмоциональные беседы о том же либерализме (примеры в тексте). Локальный Nous Hermes Solar выдал изумительную аннотацию на Хаварда Блюма "Принцип Люцифера" из "своей" памяти(!) и тп
Красота. ИИ на службе человека. Человек этот проживает в Вашингтоне.
именно
Какая прелесть ...
Аннотация автора статьи однозначно лучше.
С другой стороны, имея в своём счастливом советском научном детстве опыт намывания второй зарплаты на рефератах в ВИНИТИ, могу сказать, что реферат от арифмометра был бы удовлетворительным, и позволяет пользователю соориентироваться, "обо что этот фильм, ну там дюдик, или про любоф, или про войну, или комедь?", и при необходимости обратиться к оригиналу.
"Был бы" потому, что в наличиии явный минус реферата от арифмометра - нет ни одной цифры, и ключевых параметров методики исследования, при том, что в аннотации от авторов исследования это есть, и при тупом переводе оригинальной аннотации гарвардской статьи пользователь получил бы больше информации. Нормальный, а не удовлетворительный, реферат был бы, если бы оригинальная аннотация исследования не содержала цифр и методики, а рефератчик их бы из тела статьи вытащил и вставил в реферат.
Также надо отметить, что арифмометр гоняли в типовых для консалтеров маркетинговых задачах, с накопленным колоссальным объемом академических и не очень текстов. Да и то вылезло, что "шаг вправо, шаг влево, прыжок на месте - расстрел" от начальства за косяки.
В общем, лично для меня результаты статьи укладываются в мои ожидания - за счёт большего объема оперируемой информации арифмометры позволяют пользователю минимизировать его информационные пробелы. Но не более того. Этакое грубое сито для информационных завалов.
Спасибо за оценку. но наверное, у нас с вами сравнимого уровня "академическое " - а не менеджерское образования (последнее для менеджеров нужно в кавычки )
)
Действительно - почему просто абстракт не напечатала? Возможно, предположила, что если сам не прочитал - или прочитал и не понял, значит нужно на "более высоком уровне". Модели сейчас, кстати вполне способны на такую логику. Вон, я тут недавно послал диалог комментах - это вторая попытка. В первой забыл убрать температуру и минут пять с машиной спорил по поводу того, что же на самом деле хотел сказать автор. Она была очень убедительна и неожиданно изощренна.
С машинным summary еще есть такой момент- в "человеческом" случае вряд ли удастся задать уточняющий вопрос. С машиной можно.
И для личной "продуктивности" - всегда полезно обсудить тему - или даже собственный текст. Да и в наши времена не всегда легко найти желающего внимательно слушать рассуждения на специализированную тему.
Разумеется, не стоит ожидать больше, чем от большинства обычных людей - лучше потом удивиться
А оно надо, чтобы арифмометры что-то про человеков домысливали?
Собственно, даже между безшёрстыми обезьянами это классический повод для конфликтов:
"Рыбонька, пробей билетик, пожалуйста."
Женщина думает:
"Рыбонька - значит рыба, рыба - значит щука, щука - значит хищник,
хищник - значит зубы, зубы - значит собака, собака - значит сука..."
Во весь голос: "ТОВАРИЩИ!!! Он меня сукой обозвал!!!"
надо или не надо - это вопрос, который уже решен.
Решён, или навязан разработчиками в явочном порядке, потому что они в качестве базы использовали вероятностную математику?
Анекдот про то, как от рыбки до самки собаки дошли таки не совсем анекдот, это именно частотности в контексте.
я помню когда я был очень маленьким, моя бабушка меня учила считать на арифмометре .. и в то время в их отделе появились первые электронные калькуляторы и она очень гордилась тем, что в отличие от девочек с калькуляторами, она ошибок никогда не делала. Доходило до того, что сотрудники ее просили проверить их расчеты сделанные на калькуляторах .. Но и это прошло.
Работа с моделями, особенно локальными, пока достаточно сложна и пока не 100% надежна - но это пока. Попробуйте повозиться с ними без предубеждения.
Другая проблема - многослойная цензура
Вот пример
"Фотография запечатлела ностальгический образ .."
Вобщем, независимо от того, как устроена модель - результат (при правильной настройке) практически неотличим от того что мы называем деятельностью разума. Что бы последнее не означало.
Кстати, о вероятности при построении предложений, я отчетливо помню период в глубоком детстве, когда выглядеть "умным" было для меня очень важно и поэтому говорить "нужно" было сложными, но логически правильно построенными предложениями. Я иногда "застревал" в середине неправильно выбранной конструкции, лихорадочно выискивая следующее слово и цепочку, которая позволит мне выкрутиться с наибольшим количеством вариантов и сохранить связь с началом. Ничего не напоминает?
Пример с зависанием при подборе слов иллюстрирует, что на "аппаратном уровне" мозг не приспособлен к вычислению вероятностей.
Промеж ушей аппаратно реализовано параллельное умножение вектора на матрицу, т.е. линейный классификатор. В роли вектора нейрональные отростки с десятком тысяч параллельно работающих синапсов, нейроны складываются в матрицу нейрональную колонку и далее в ядра, тоже с параллельной работой.
В линейном классификаторе свои ошибки, в виде неполного сбора признаков, и выхода ситуации за пределы ранее известного. А в вероятностных моделях свои глюки - за правильный ответ считают то, что более часто, а не то, что перед пользователем в реале.
я в этом не разбираюсь - пока, или и не буду вообще. У меня голова и так как мусорный ящик - от водорода в металлах до ядерной физики до геохимии и медицины, назвать только несколько областей, и по уши - всем что попало для решения практических проблем в промежутке в этих областях. Ах да - теперь еще и политика пытается добавиться - вот хочу машину заставить за меня читать. А я буду писать (русская шутка)
Я не вижу как, например, стандартная feedforward нейронная сеть с одним двумя промежуточными слоями - это умножение вектора на матрицу, хотя и писал и тренировал руками таковые для двух вполне практических приложений. И они работали. Будет надо - разберусь и пойму Пару лет назад делал руками линейный бинарный классификатор - прямо на VBA в Excel для вполне конкретной практической задачи - и он работал великолепно, лучше, чем автоматически тренированный каким-то новым (тогда) и таинственным пакетом МАТЛАБА - думать про линейную алгебру с дюжиной параметров почему-то тоже не было надо. Будет надо - разберусь и буду думать "как надо" если надо. Сейчас у меня NLP и я только начал разбираться, может быть потом я пойму что вы тут написали - и зачем оно нужно. Пока материала слишком много и я просто разбираюсь а здесь поделился опять же практическим приложением и показал (на мой взгляд) что это может делать каждый - по крайней мере на уровне пользователя "калькулятора" из истории про бабушку которую я рассказывал, так что не обессудьте .
Пару лет назад делал руками линейный бинарный классификатор - прямо на VBA в Excel для вполне конкретной практической задачи - и он работал великолепно, лучше, чем автоматически тренированный каким-то новым (тогда) и таинственным пакетом МАТЛАБА - думать про линейную алгебру с дюжиной параметров почему-то тоже не было надо. Будет надо - разберусь и буду думать "как надо" если надо. Сейчас у меня NLP и я только начал разбираться, может быть потом я пойму что вы тут написали - и зачем оно нужно. Пока материала слишком много и я просто разбираюсь а здесь поделился опять же практическим приложением и показал (на мой взгляд) что это может делать каждый - по крайней мере на уровне пользователя "калькулятора" из истории про бабушку которую я рассказывал, так что не обессудьте .
Вопрос представления понятий, то ли нейросети как графы, то ли как вектора с матрицами, то ли вообще множественные слои из матриц, но это уже не настолько универсально из-за ограничений на размерности перемножаемых матриц, да ещё накопление глюков на каждом из слоёв.
В любом случае на "аппаратном уровне" в мозге синапсы сидят на нейрональных отростках нейронов, нейроны с отростками сложены в нейрональные колонки, и всё шарашит параллельно. Что математически полностью соответствует умножению вектора на матрицу.
И ещё раз в любом случае - как только подмешивают вероятности, возникает системный пробой "правильно то, что часто", при этом большая вероятность одного события не вычеркивает из реальности менее частые события. Грубый пример - некий антибиотик помогает у 80% пациентов, но это не значит, что у 20% пациентов не надо будет менять терапию, или что врач убийца в белом халате и его надо под суд.
это, скорее, на другую тему .. (но мне понравилось). Я уже писал, что мне не удалось определить "среднего" пациента с sleep aponea по большой базе данных Среднее, конечно, есть - но его дисперсия как у распределения Коши. А в 80% и 20% все вероятности условные - "помогает при услови (-ии -ях) что.. " , поэтому условные 80% тоже при условии. Включая, вероятность того, что и первую терапию возможно можно было не назначать https://www.sciencedirect.com/topics/medicine-and-dentistry/psychoneuroimmunology . Как нибудь потом при случае обсудим, наверное .. (сейчас занят)
https://www.sciencedirect.com/topics/medicine-and-dentistry/psychoneuroimmunology . Как нибудь потом при случае обсудим, наверное .. (сейчас занят)
Про уголовную ответственность врачей согласен ~ уголовная ответственность только при доказанной намеренности причинить вред. В целом врач должен просто давать рекомендации и обязательно подчеркивать (и понимать сам), что он - не Бог (и даже не бюрократ из министерства, который всегда знает всё даже лучше Бога). Сейчас это не совсем модель поведения большинства практикующих врачей с пациентом. Ответственность должна быть на пациенте. По-моему, сейчас в России примерно этими поправками и занимаются?
В медицине надо быть спецом в определённой категории болячек, чтобы хотя бы задним числом интерпретировать, почему конкретный пациент попал в 80%, или, напротив, в 20%. А чисто математически это глушняк.
Вообще то имитатр интеллекта(или арифмометр) "без человека" вообще ничего не генерирует
я вам щас отвечу как
меня научилимне напомнили недавно - "да"И мне приятно ответить вам "да" в ответ на:
именно так
А на чем вы разворачивание вот эти все вот модели локально?
многие модели до 6-8 GB дают удивительно хорошие результаты на Intel© Core™ i7-4790S CPU @ 3.20GHz × 4 c 16GB DDDR3 даже без CUDA под Ubuntu. Другая машина АМД 5700х с 128GB DDR4 памяти и RTX 2070Ti, тоже Ubuntu. На этой можно грузить даже не квантизированные модели практически любого размера из доступных, и карта, хотя и слабая по нынешним временам, заметно помогает, когда ее подключаешь. На этом работать вполне комфортабельно быстро. Есть и другие машины где-то по середине классом. .. Под Windows 11 я не слишком внимательно гонял, работало не очень быстро, индексацию локальных документов и работу с ними постоянно глючило (а меня именно они и интересуют и я с методами разбираюсь на данном этапе) и возиться не хотелось - мне на линуксе удобнее и спокойнее.
ЗЫ в статье, если обратили внимание - в основном web interface c Copilot in MS Edge browser - машина у них "там". И пока бесплатно. Последняя свертка в статье действительно на локальных моделях и, по-моему, на процессоре только
ЗЫ2 кстати, executable под Windows по-моему ограничен 4GB, поэтому, например llamafile (на картинке с из демократической Бельгии в моем комменте выше) без отделения весов загрузится не со всеми моделями - только с "маленькими". В линуксе этой проблемы нет.
А какfя модель на ваш взгляд самая непритязательная и адекватная?
текстовая.
я не занимался систематическим анализом и вобщем недавно начал - поэтому определенно советовать не могу. Наверное, это в первую очередь будет зависеть от того, что вы от нее хотите - на HuggingFace много моделей специально fine-tuned на завершение/написание программного кода, например и тп - я такие не гонял. Меня сейчас больше интересует классификация и анализ текста по вполне прагматическим причинам. Для этих целей я бы сказал подойдет "любая нецензурная" модель, достаточно большая, чтобы нормально "разговаривать". Мне показалось, что для анализа локальных документов главная проблема в предварительной обработке текста и токенизации еще до того как он попадает в основную модель. Я сейчас с этим разбираюсь - только начал, на самом деле.
модель, достаточно большая, чтобы нормально "разговаривать". Мне показалось, что для анализа локальных документов главная проблема в предварительной обработке текста и токенизации еще до того как он попадает в основную модель. Я сейчас с этим разбираюсь - только начал, на самом деле.
Просто попробовать - начните что-нибудь делать, не просто читать - почитайте например Касперского статью, почитайте про нецензурные модели .. и почему они нужны здесь .Того же wig прямо здесь на Aftershock на русском. Начните с GPT4ALL (это приложение, не ChatGPT4 ). Там полностью GUI и код писать не нужно, но можно посмотреть как влияют разные "внешние" параметры и как ведут себя разные модели - ну и главное, почувствовать себя более комфортабельно - важно в начале
). Там полностью GUI и код писать не нужно, но можно посмотреть как влияют разные "внешние" параметры и как ведут себя разные модели - ну и главное, почувствовать себя более комфортабельно - важно в начале .. Использует GGUF (веса уже встроены в модель). Он плохо работает с локальными документами, есть баги - но проект "живой", они работают. Имейте в виду, что он (по-моему) работает (пока) только с квантизацией 4_0 - но зато модели можно грузить прямо из GUI кликая кнопочки.
.. Использует GGUF (веса уже встроены в модель). Он плохо работает с локальными документами, есть баги - но проект "живой", они работают. Имейте в виду, что он (по-моему) работает (пока) только с квантизацией 4_0 - но зато модели можно грузить прямо из GUI кликая кнопочки.
Есть забавный проект LLAMAFILE "всё в одном файле" Там множество опций - от локального сервера для чата и документов до картинок. Минимальное количество кода, внятная документация и то, что компилируется легко посмотреть при желании. Для локального деплоймента очень удобно - машину можно полностью изолировать (оторвать интернет) после установки проекта .. и тп
Для мазохистов способных ждать минутами ответ в чате - можно GPT4ALL (это НЕ GPT4!!) и какую-нибудь модель в нем даже на Raspbery Pi запустить (я не мазохист поэтому не пробовал )
)
Спасибо!
По текстовым моделям не скажу, но если интересно по задаче генерации картинок то расклад по Stable Diffusion такой:
Nvidia с 6 Gb vram - уже можно генериртвать изображения, на древней gtx 1660 super минут 5 на изображение получится.
16 Gb видеопамяти - уже можно обучать свои Lora слои для 1024x1024 разрешения SDXL сети. На Nvidia 4060ti 16Gb изображение за несколько секунд генерирует. Lora за полтора-два часа обучается.
Процессорной оперативной памяти желательно больше 40 Гб, иначе будет сильно стачивать ресурс ssd/nvme.
Разворачивал под виндой, там пайтон веб-приложения, с которыми в браузере взаимодействуешь потом.
я пока с текстом работаю - но, да, хотел бы с картинками повозиться. Дойдут руки - спрошу у вас для начала
Попробуйте https://github.com/oobabooga/text-generation-webui
Мне нравится модель vicuna vizard 13b uncensored
Спасибо!
Какая версия GPT тестировалась? Это очень важный нюанс.
в первых двух примерах (свертках в тексте) - я ее только что спросил - она сказала "последняя версия" GPT4 "очень безопасная"
- она сказала "последняя версия" GPT4 "очень безопасная" 
в локальных примерах (последняя свертка в тексте) - orca-mini-3b-gguf2-q4_0 и dolphin2x5 4_K_M- не GPT совсем
Обсуждаемое поле здесь, надо полагать, торсионное.
Поскольку в неальтернативной реальности полевые данные получают геологи, биологи, географы - но уж никак не погромисты.
" Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality"
".. критикуешь - предлагай .." (тм) Предложите лучший перевод. Да, звучит диковато, но мне было лень придумывать, тем более что они действительно работали " в поле" - в реально существующей компании с их продуктом (обувью_ и с их людьми.
Предлагаю. Имеет место классическая подмена понятий. Которую, вместо чтобы
гонять ссаными тряпками обратно на западэнщинуразоблачать, тиражируют.На этом у меня всё.
Renée Newman
International Jewelry Publications
Gem & Jewelry
POCKET GUIDE
A traveler’s guide to buying diamonds, colored gems, pearls, gold and platinum jewelry